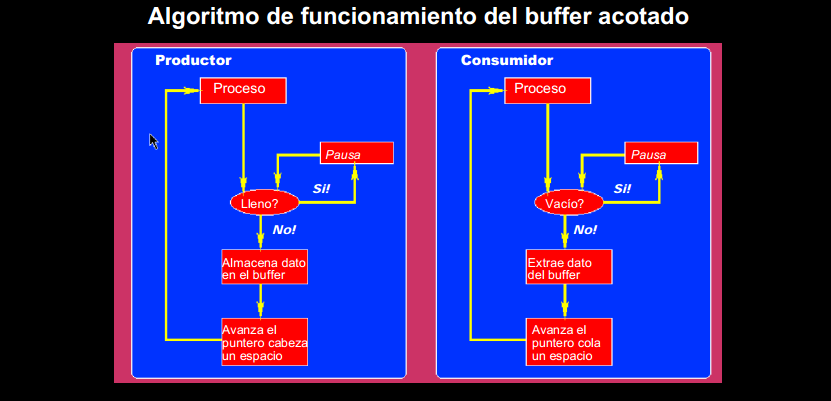
FILESYSTEM
Los sistemas de archivos o ficheros, estructuran la
información guardada en una unidad de almacenamiento, que luego será
representada ya sea textual o gráficamente utilizando un gestor de archivos. La
mayoría de los sistemas operativos manejan su propio sistema de archivos.
Lo habitual es utilizar dispositivos de almacenamiento de
datos que permiten el acceso a los datos como una cadena de bloques de un mismo
tamaño, a veces llamados sectores, usualmente de 512 bytes de longitud (También
denominados clústers). El software del sistema de archivos es responsable de la
organización de estos sectores en archivos y directorios y mantiene un registro
de qué sectores pertenecen a qué archivos y cuáles no han sido utilizados. En
la práctica, un sistema de archivos también puede ser utilizado para acceder a
datos generados dinámicamente, como los recibidos a través de una conexión de
red (sin la intervención de un dispositivo de almacenamiento).
En algunos sistemas de archivos los nombres de
archivos son estructurados, con sintaxis especiales para extensiones de
archivos y números de versión. En otros, los nombres de archivos son
simplemente cadenas de texto y los metadatos de cada archivo son alojados
separadamente.
QUEMAR UN CD
Quemar un CD es una expresión usada como sinónimo de grabar
información dentro del mismo. Se dice que se “quema” un disco compacto porque
el proceso de grabación utiliza un láser que calienta la superficie del disco
en el proceso, “quemando” la información en este.
Grabado por acción de láser
Otro modo de grabación es por la acción de un haz láser
(CD-R y CD-RW, también llamado CD-E).
Para esto la grabadora crea unos pits y unos lands cambiando
la reflectividad de la superficie del CD. Los pits son zonas donde el láser
quema la superficie con mayor potencia, creando ahí una zona de baja
reflectividad. Los lands, son justamente lo contrario, son zonas que mantienen
su alta reflectividad inicial, justamente porque la potencia del láser se
reduce.
Según el lector detecte una secuencia de pits o lands,
tendremos unos datos u otros. Para formar un pit es necesario quemar la
superficie a unos 250º C. En ese momento, el policarbonato que tiene la
superficie se expande hasta cubrir el espacio que quede libre, siendo
suficientes entre 4 y 11 mW para quemar esta superficie, claro que el área
quemada en cada pit es pequeñísima.
Grabado por acción de láser y un campo magnético
El último medio de grabación de un cd es por la acción de un
haz láser en conjunción con un campo magnético (discos magneto-ópticos).
Los discos ópticos tienen las siguientes características,
confrontadas con los discos magnéticos:
Los discos ópticos, además de ser medios removibles con
capacidad para almacenar masivamente datos en pequeños espacios -por lo menos
diez veces más que un disco rígido de igual tamaño- son portátiles y seguros en
la conservación de los datos (que también permanecen si se corta la energía
eléctrica). El hecho de ser portables deviene del hecho de que son removibles
de la unidad.
MEMORIAS USB
Las memorias flash basadas en puertas lógicas NAND usan un
túnel de inyección para la escritura y para el borrado un túnel de ‘soltado’.
Las memorias basadas en NAND tienen, unas diez veces de más resistencia a las
operaciones pero sólo permiten acceso secuencial (más orientado a dispositivos
de almacenamiento masivo), frente a las memorias flash basadas en NOR que
permiten lectura de acceso aleatorio. Sin embargo, han sido las NAND las que
han permitido la expansión de este tipo de memoria, ya que el mecanismo de
borrado es más sencillo (aunque también se borre por bloques) lo que ha
proporcionado una base más rentable para la creación de dispositivos de tipo
tarjeta de memoria. Las populares memorias USB o también llamadas Pendrives,
utilizan memorias flash de tipo NAND.
La información en las memorias NAND Flash, se almacena en
Celdas y cada una de estas celdas tienen un tiempo de vida determinado que se
expresa en ciclos de escritura, si bien no son eternas estas celdas, los ciclos
de escritura aseguran una vida útil, mas allá de lo que demoremos en actualizar
el dispositivo. Es así que dependiendo del tipo de memoria NAND Flash (MLC o
SLC) las celdas pueden tener 10.000 o 100.000 ciclos de escritura por sector
físico, llegando a ser mas que suficientes 10.000 ciclos para borrar y escribir
completamente el contenido de un array de celdas en un chip de memoria Nand
Flash, una vez por día durante 27 años.